Lemmatizer
Lemmatizer is located under Textual Analysis in Pre Processing, in the task pane on the left. Use drag-and-drop method to use algorithm in the canvas. Click the algorithm to view and select different properties for analysis.
Lemmatizer is an algorithm in morphological analysis and computational linguistics which identifies the lemma (or the dictionary form) of a word. In lemmatization, all the inflected forms of a word are grouped together so that they can be identified as a single item.
Lemmatization algorithms identify the intended part of speech as well as the meaning of a word in a sentence, as also in a larger context in the surrounding sentences and even the entire document.
Properties of Lemmatizer
The available properties of Lemmatizer are as shown in the figure given below.
The table given below describes different fields present on the properties of Lemmatizer.
Field | Description | Remark | |
|---|---|---|---|
| Run | It allows you to run the node. | - | |
| Explore | It allows you to explore the successfully executed node. | - | |
| Vertical Ellipses | The available options are
| - | |
Task Name | It displays the name of the selected task. | You can click the text field to edit or modify the name of the task as required. | |
Text | It allows you to select the text for which you want to perform lemmatization. |
| |
| Advanced | Node Configuration | It allows you to select the instance of the AWS server to provide control on the execution of a task in a workbook or workflow. | For more details, refer to Worker Node Configuration. |
Interpretation of Lemmatizer
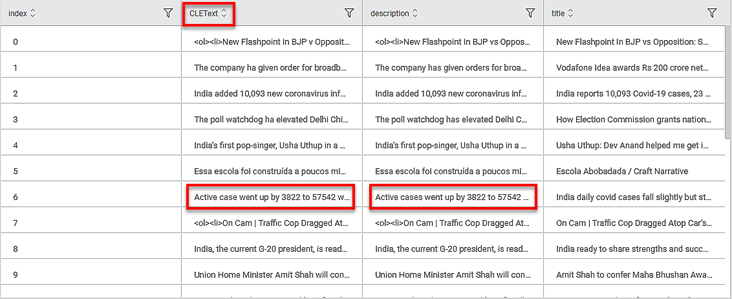
The figure given below shows the result of Lemmatizer applied on Google News snippets.
In the figure, the column heading CLEText represents the text after the Lemmatizer is applied.
In the highlighted example, the word "cases" has been reduced to its lemma "case".
Related Articles
Lemmatizer
Lemmatizer is located under Textual Analysis in Pre Processing, in the task pane on the left. Use drag-and-drop method to use algorithm in the canvas. Click the algorithm to view and select different properties for analysis. Lemmatizer is an ...