Mapping Variables
In Rubiscape, you can create, train, test, and publish models for further use in workbooks or workflows. For this, we configure a model using a dataset. When you publish a trained model, it appears in the model section under Model Studio or Machine Learning.
When you connect a reader (dataset) to a published model, you map the reader variables with the model variables. This mapping should occur according to the internal configuration of the model. If the configured variables are accurately mapped through the reader, the model is published successfully, and you get accurate results.
Notes: |
|
For example, consider a published model Poisson_Regression and a reader BicycleCountData. The two nodes are connected to map the reader and model variables.
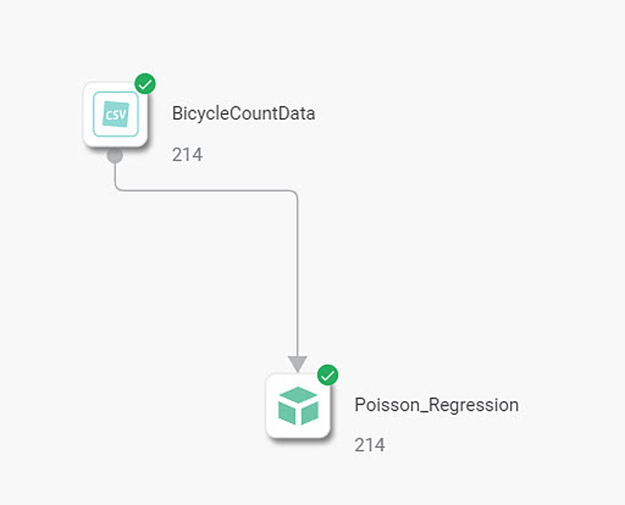
When you click the reader node, you see the Reader Properties in the right-hand pane.
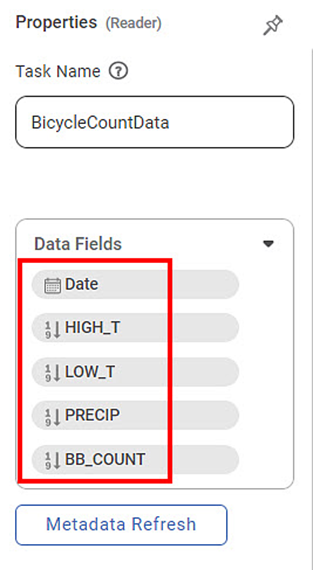
The Data Fields contain a list of reader variables in the sequence they appear in the dataset. Thus, Date is the first reader variable, and BB_COUNT is the last variable in the sequence.
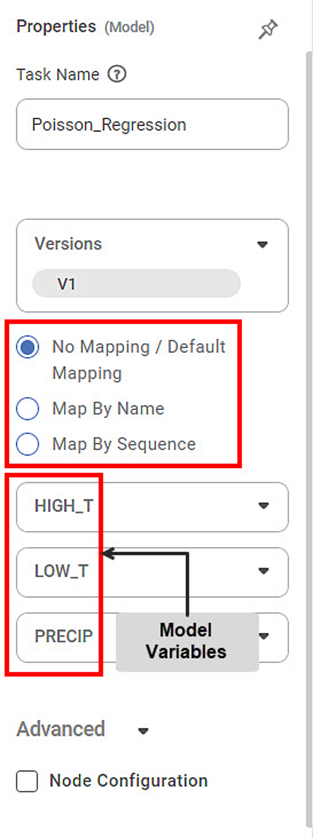
When you click the model node, you see the Model Properties in the right-hand pane.
In this pane, the radio buttons for the mapping options are available. These are
No Mapping/Default Mapping
Map By Name
Map By Sequence
You also see the variables present in the published model. (These variables are derived from the dataset used to train the model.)
For example, the model Poisson_Regression contains the following three variables.
HIGH_T
LOW_T
PRECIP
The dropdown for each model variable contains a sequential list of reader variables. This list is used for manual mapping of the reader variables with each model variable.
The table below describes the three types of Mapping Options.
Table: Description of Variable Mapping Options
Mapping Options | Description | Remark |
No Mapping/ Default Mapping | It allows you manually map the reader and model variables. |
|
Map By Name | It automatically maps the reader and model variables having the matching name. |
|
Map By Sequence | It automatically maps the model variables with the reader variables in the sequence in which they appear in the reader. |
|
Notes: |
|
Mapping Options
There are three types of options for mapping reader variables to the model variables. These are
No Mapping/Default Mapping
Map By Name
Map By Sequence
The effect of these mapping options is shown below.
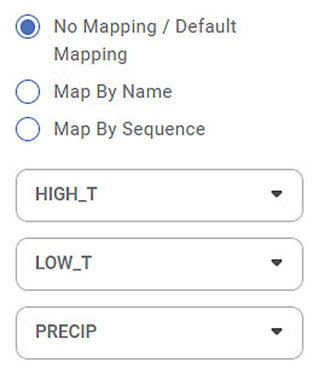
No Mapping/Default Mapping:
This option is selected by default. In this option, you see that none of the model variables are mapped to any reader variable.
However, you can click the model variable dropdown and map the reader variables from the list with each model variable.
Notes: |
|
Map By Name:
When you select the Map By Name button, the reader variables are mapped with model variables possessing matching names. This mapping helps align the test data (reader) with the trained model.
For example, the reader variable PRECIP is mapped to the model variable PRECIP in the image below.
This mapping option yields no result if the names of model variables and reader variables are completely different.
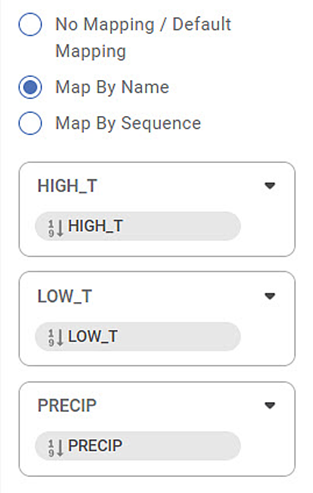
Map By Sequence:
When you select the Map By Sequence option, the reader variables are sequentially mapped (in which they appear in the reader dataset) to the model variables.
For example, in the image below, the reader variable Date is mapped to the model variable HIGH_T, the reader variable HIGH_T to model variable LOW_T, and the reader variable LOW_T to the model variable PRECIP.
In this mapping option, if the number of model variables is more than the number of reader variables, the excess model variables remain unmapped.
Related Articles
Mapping Variables
In Rubiscape, you can create, train, test, and publish models for further use in workbooks or workflows. For this, we configure a model using a dataset. When you publish a trained model, it appears in the model section under Model Studio or Machine ...Geographical Variables
In RubiSight, you can use Numerical, Textual, Interval, Categorical, and Geographical types of variables. Creating a Dataset with Geographical Variable Type To create a dataset containing a geographical variable type, follow the steps given below Add ...Configuring Display Unit Mapping
Display Unit Mapping-Formatter To display chart labels/tooltip values/axis labels and such applicable values wherein the display unit is displayed, the formatter -Display Unit Mapping is available in the page level Format pane options. (To Navigate: ...Using Variables in RubiPython
The variables defined at the workbook/pipeline level can be used in the RubiPython custom component. To use a user-defined variable in RubiPython, follow the steps given below. Create your algorithm flow. Refer to Building Algorithm Flow in a ...Usage of Variables
In Rubiscape, you can add a variable at the workbook or workflow level. Refer to Adding a Variable. Rubiscape provides variable support, that is, its usage, for all tasks anywhere in workbooks or workflows like creating a dataset, performing data ...