Missing Value Imputation
Missing Value Imputation | |||||
Description | Missing value imputation is the attribution of values in place of missing values in a real-world dataset. | ||||
Why to use | Numerical Analysis – Data Preparation | ||||
When to use | When there are missing values in the data. | When not to use |
| ||
Prerequisites | It should be used on numerical data. | ||||
Input |
| Output |
| ||
Statistical Methods used |
| Limitations |
| ||
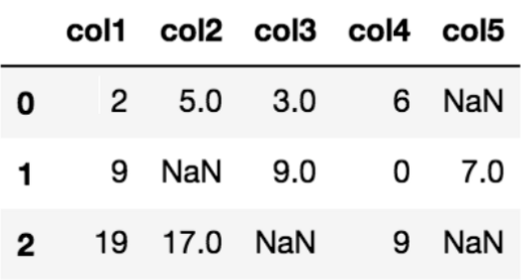
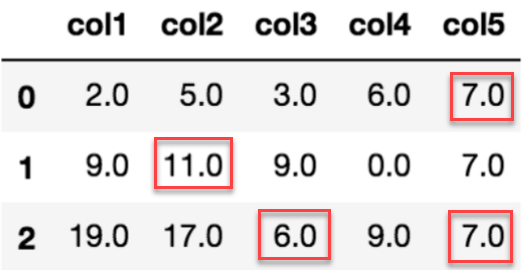
There are many ways data can end up with missing values. For example
- A 2-bedroom house would not include an answer for "How large is the third bedroom?"
- Someone being surveyed may choose not to share their income.
Python libraries represent missing numbers as NaN which is short for "not a number".
Most libraries (including scikit-learn) will give you an error if you try to build a model using data with missing values. So, you will need to choose one of the strategies to impute missing values.
Missing value imputation is the attribution of values in place of missing values in a real-world dataset.
Many times, there are missing values in datasets. These datasets are incompatible for scikit estimators because these estimators assume that all values are meaningful numerical values. If we eliminate the rows in a dataset containing missing values, we may lose important and relevant data. Hence, missing value imputation fills the missing gaps by inferring the value from the known part of the data.
Missing value imputation can be univariate or multivariate. In univariate imputation, the missing value is replaced by a constant value or a statistical value like the mean or the median of the corresponding column. In multivariate imputation, each feature with missing value is modeled as a function of other features, and then this estimate is used for imputation.
Related Articles
Missing Value Imputation
Missing Value Imputation Description Missing value imputation is the attribution of values in place of missing values in a real-world dataset. Why to use Numerical Analysis – Data Preparation When to use When there are missing values in the data. ...Time-series Data Preparation Tests in Forecasting
The different tests available in Time-series Data Preparation under Forecasting are given below. Accumulation Missing Value Transformation Differencing Data Preparation Description The time-series data may contain missing values that need to be ...Random Forest Regression
Random Forest Regression Description Random Forest Regression is an ensemble learning method that combines multiple decision trees to create a powerful predictive model for continuous target variables. It utilizes random feature selection to improve ...Decision Tree Regression
Decision Tree Regression Description Decision Tree Regressor builds a regression model in the form of a tree structure where each leaf node represented a class or a decision. Why to use When you want to predict a value depending on single or multiple ...Time-series Data Preparation
Time-series Data Preparation organizes and formats transactional data into time-series data to predict trends and seasonality in the data. Transactional data is timestamped data recorded over a period at no specific frequency, while time-series data ...