Rubiscape provides the functionality to create a dataset using Twitter data. On this data, you can perform Twitter Sentiment Analysis using the text processing algorithms provided in Text Analytics. The sentiment analysis helps to determine the tone (Neutral, Positive, Negative) of the tweet and thereby gives beneficial insights about market trends and competitors' policies. This, in turn, helps the decision-makers to create marketing strategies. To perform Twitter Sentiment Analysis, Rubiscape uses Tweepy, a Python library designed to access the Twitter API. A request to the Twitter API returns the Tweet fields (Features), which can then be analysed using Text Analytics.
To create a Twitter dataset, follow the steps given below.
- On the home page, click Create icon (
 The Product Selection page is displayed.
The Product Selection page is displayed. - Hover over the Data Connect tile, and click Create Dataset.
 The Dataset Selection page is displayed.
The Dataset Selection page is displayed. - From the Social Media option, select Twitter.
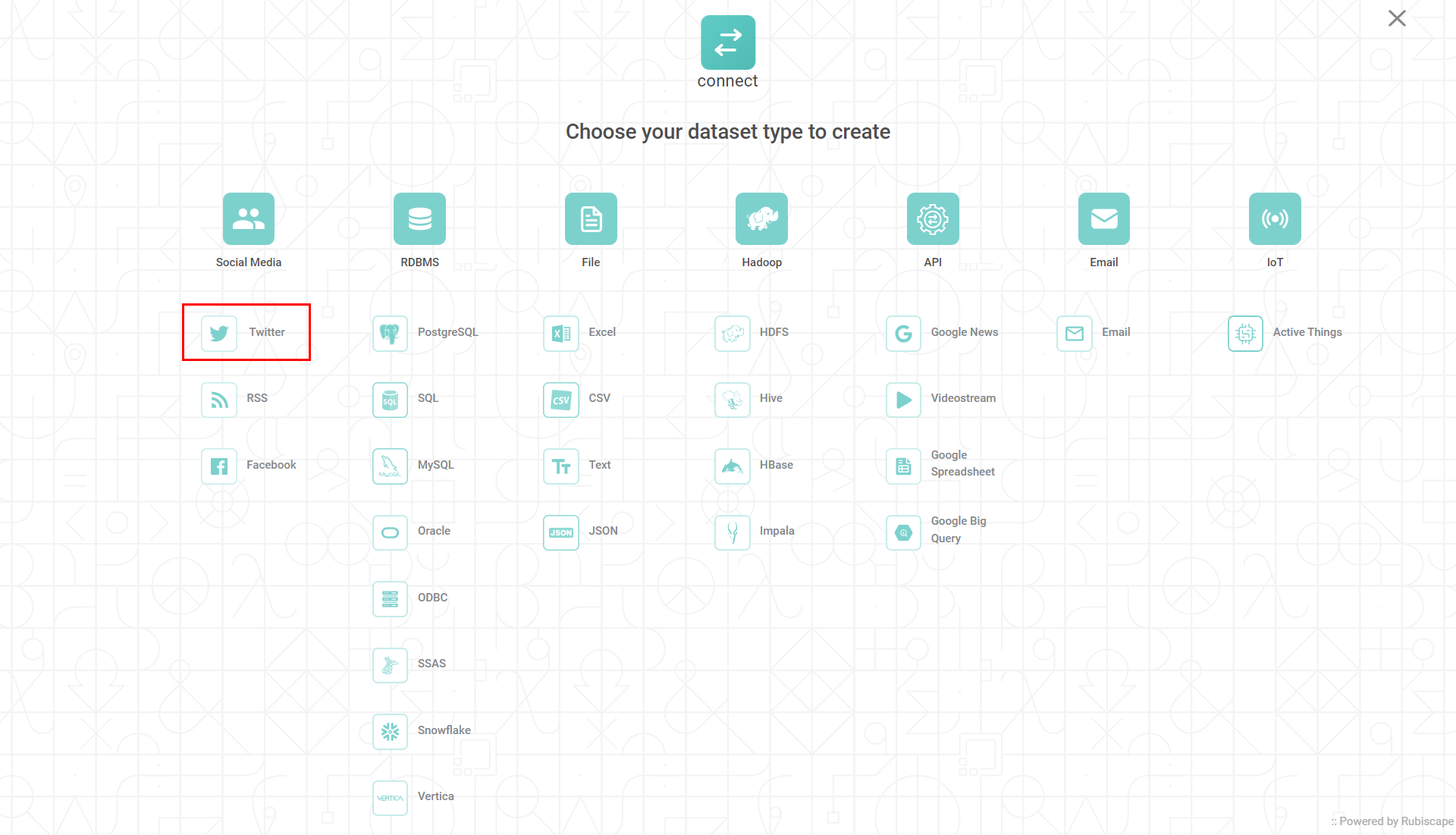
Create Twitter Dataset page is displayed. - Enter the Name of the dataset.
Enter the Description for the dataset.
Enter the Hashtag # for which you want to pull the data. Multiple hashtags can be used, separated by a comma.
Enter the API Key to access the data from twitter platform.
Enter the API Secret of the twitter account.
Enter the Access Token of the twitter account.
Enter the Access Secret of the twitter account.
Click on Verify.
The table given below explains the Features available for the Twitter dataset.Features of the Twitter dataset collected by Rubiscape
tweet_id
The unique identifier for the tweet.
user_id
The unique identifier for the user who posted the tweet.
tweet
The actual text of the tweet.
username
The name of the twitter handle that posted the tweet.
language
The language of the tweet.
location
The location from where the tweet was posted.
place
The place the tweet is associated with. This place is not necessarily the place from where the tweet was posted.
device
The device used to post the tweet.
retweet
This field represents whether the tweet is a retweet or not. Possible values are True and False.
retweetcount
In the case of a retweet, this field represents the number of times the tweet has been retweeted.
reply_to_userid
If the represented tweet is a reply, this field represents the original Tweet's author ID.
reply_to_statusid
If the represented tweet is a reply, this field represents the integer representation of the original Tweet's ID.
time
The date and time of the tweet.
Click Create after successful verification.
The Twitter dataset is created in Rubiscape and is available for use in your workbooks and workflows.
- To obtain the API Key, API Secret, Access Token, and Access Secret, you need to create a Twitter Developer Account.
- Enabling the "Disable Cache" option allows you to create a dataset without generating a dataset cache.
- When you select to "Disable Cache", the dashboard will not offer the "Enable Direct Query" option. For more information, please refer to the "Enable Direct Query" document
Related Articles
Adding a Dataset
A dataset is global and shared across the same workspace. Consider adding a dataset before creating a project. You can add a dataset from the supported data sources. The added datasets can be used in multiple projects. To add a dataset, follow the ...Batch Processing
Pipeline allows you to divide the dataset/Tasks into batches and then process it. Batch processing is mainly used to simplify many ETL operations like Missing value Imputation, expression, and validating data. You can specify the batch size called ...Batch Processing
Working with Batches Workflow in Data Integrator allows you to divide the dataset into batches and then process it. Batch processing is mainly used to simplify many ETL operations like Missing value Imputation, expression, and validating data. You ...Custom Word Remover
Custom Words Remover is located under Textual Analysis in Pre Processing, in the task pane on the left. Use drag-and-drop method to use algorithm in the canvas. Click the algorithm to view and select different properties for analysis. One of the ...Custom Word Remover
Custom Words Remover is located under Textual Analysis in Pre Processing, in the task pane on the left. Use drag-and-drop method to use algorithm in the canvas. Click the algorithm to view and select different properties for analysis. One of the ...