Cross Validation
Cross Validation is located under Model Studio (.png) ) under Sampling, in Data Preparation, in the left task pane. Use the drag-and-drop method to use the algorithm in the canvas. Click the algorithm to view and select different properties for analysis.
) under Sampling, in Data Preparation, in the left task pane. Use the drag-and-drop method to use the algorithm in the canvas. Click the algorithm to view and select different properties for analysis.
Refer to Properties of Cross Validation.
Properties of Cross Validation
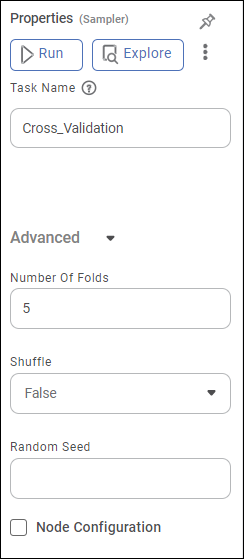
The table given below describes the different fields present on the properties of Cross Validation.
Field | Description | Remark |
|---|---|---|
| Run | It allows you to run the node. | - |
| Explore | It allows you to explore the successfully executed node. | - |
| Vertical Ellipses | The available options are
| - |
Task Name | It is the task selected on the workbook canvas. | You can click the text field to edit or modify the name of the task as required. |
Number Of Folds | It allows the dataset to be split into the given number of folds. | — |
Shuffle | It allows you to select whether or not to shuffle the input data while creating the different folds. | Its values are either True or False. True: The data is shuffled before splitting into folds. False: The data is not shuffled before splitting into folds. |
Random Seed | It is the value that builds a pattern in random data. This ensures that the data is split in the same pattern every time the code is re-run. | — |
Example of Cross Validation
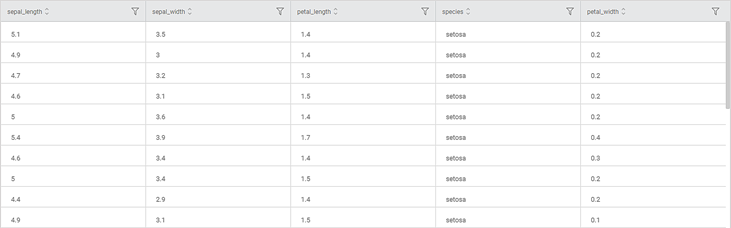
Consider a flower dataset with 150 records. A snippet of input data is shown in the figure given below.
We apply Cross Validation to the input data. The output of Cross Validation is given as input to the Regression model, Ridge Regression.
The result displays the Regression Statistics for each of the folds, as shown in the figure below.
The final score for each of the different metrics on complete data is also displayed.
The result also displays Fold-wise Cross Validation (CV) Score, Standard Deviation, and Mean Score of all the CV scores.
Similarly, you can use Train Test Split and test any other Classification or Regression models.
Related Articles
Cross Validation
Cross Validation is located under Model Studio () under Sampling, in Data Preparation, in the left task pane. Use the drag-and-drop method to use the algorithm in the canvas. Click the algorithm to view and select different properties for analysis. ...Support Advance Sort with Grand Total Column in Cross Table
Refer Advance Sort for configuring sorting on the widgets. Cross Table has additional configuration in Advance Sort, to add sorting condition based on the Column Grand Total. To understand the configurations, follow the below steps: 1. Plot cross ...Workbook Validation
In Rubiscape, you can drag-and-drop algorithms and datasets on the workbook or workflow canvas to build a model. When you run the model, Rubiscape validates it before execution. The validation feature is used to notify the validation errors that ...Workbook Validation
In Rubiscape, you can drag-and-drop algorithms and datasets on the workbook or workflow canvas to build a model. When you run the model, Rubiscape validates it before execution. The validation feature is used to notify the validation errors that ...Model Validation
Model validation is an enhancement of publishing a model. You can use this feature to explore the result of the published model for a selected dataset. In model validation, you can use the published model for the selected algorithm with the same ...