Profile
Overview:
The Profile node provides statistical
summaries and visual insights for selected columns in a dataset. It helps users
understand distributions, missing values, and basic metrics before further
transformations.
Location:
Pipeline → Data Preparation → Profile
Predecessor Rules:
• Only a single predecessor is allowed.
• Predecessor must output tabular data.
• Works with all RDBMS datasets, template file readers, and template table
readers.
Feature Selection:
• Features can be selected only from the
property pane.
• Selected columns appear visually inside the Profile node.
• Works after renaming, filtering, or metadata refresh.
Execution:
On execution, the node calculates basic
statistics for each selected column.
Statistics and charts appear in Explore view → Result tab.
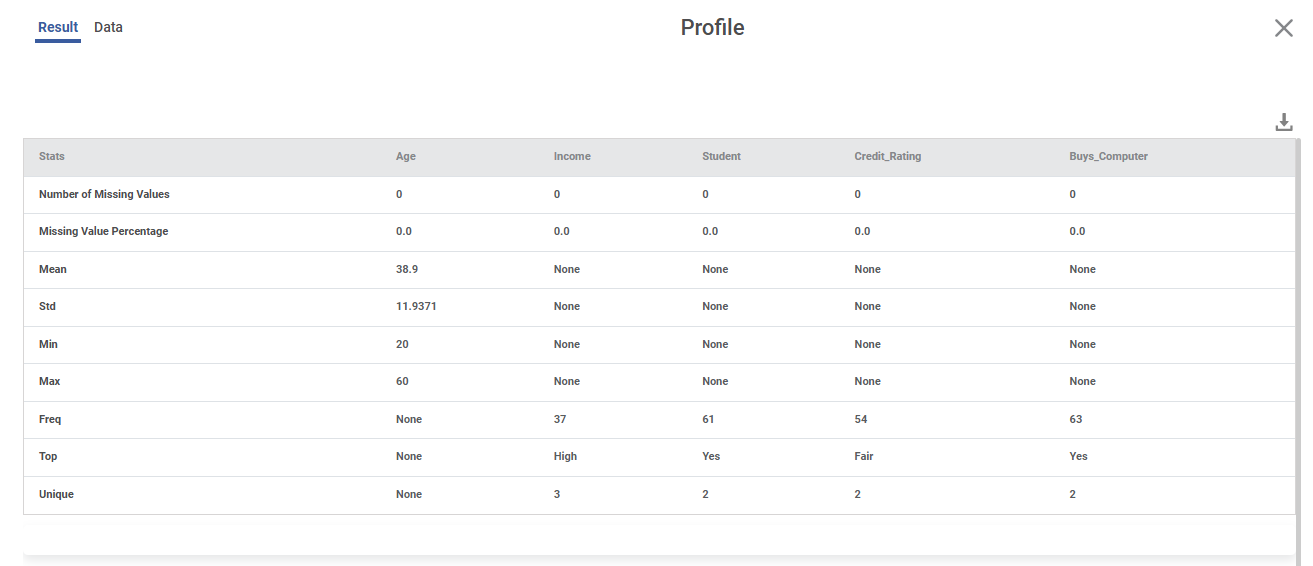
Statistics Generated:
• Missing Values
• Missing Value %
• Mean
• Std
• Min
• Max
• Freq
• Top
• Unique
Rules:
• For categorical/geographical/interval columns → Mean, Std, Min, Max = None
• For numerical columns → Freq, Top, Unique = None
Related Articles
RubiSight Mobile Application – Home Screen
RubiSight Mobile Application – Home Screen · The Home Screen is the default landing page after you log in to the RubiSight Mobile Application. · It provides quick access to dashboards, recent activity, and navigation menus for seamless exploration of ...RubiSight Mobile Application- Prerequisites and Installation
? 1. Overview The Rubiscape Mobile Application enables users to access RubiSight dashboards, analytics, and insights directly from their mobile devices. It provides a secure and convenient way to view data, monitor KPIs, and receive notifications on ...Rubisight Mobile Application- Server & Workspace Management
Server & Workspace Management This section explains how to manage servers, login details, and workspaces in the RubiSight Mobile Application. It covers server switching, adding new servers, editing server details, and managing login accounts. 1. User ...Understanding the Application Home Page
Your home page is the default workspace assigned to you as a user. The home page has four panes and a quick tour icon, as given below. Title pane: This pane displays options to go to the home page and change the workspace. It also displays options to ...Managing Users
You can view your Tenant's users, groups, and roles in the User space. The four clickable KPI Cards for Live User Sessions, Users, Groups, and Roles take you to the respective tabs on the User Page. You can see a User Sessions chart on each of the ...